AML Agnosticism
The mpi-sppy package provides callouts so that algebraic modeling languages (AMLs) other than Pyomo can be used. A growing number of AMLs are supported as guest languages (we refer to mpi-sppy as the host). This code is in an alpha-release state; use with extreme caution. This is referred to as tight integration with the guest.
It is also possible to simply read scenario data from an mps file and the mps file (and the associated json nonant file) that can be created however you like. This is refered to as loose integration and seems to be fairly robust.
Loose integration
You can use generic_cylinders.py with --mps-files-directory
as the first argument (the module mpisppy.problem_io.mps_module is
inferred automatically, so --module-name is not needed). The number
of scenarios is obtained by counting the model files (.lp or .mps)
in the directory given. When both a .lp and a .mps file are present
for the same scenario, the .lp file is used.
The file examples.loose_agnostic.AMPL.farmer_example.bash has three
commands. The second illustrates how to instruct MPI-SPPY to read
mps/json file pairs for each scenario from a directory. The first runs
an AMPLpy program that creates the scenario files. This program is
in examples.loose_agnostic.AMPL.farmer_writer.py and, apart from
the scenario_creator function, is pretty general for two-stage
problems. You be able to copy the program and
write a scenario_creator function for your two-stage problem.
The third command runs a script that illustrates how to map column
names created by the MPS writer back to AMPL variable names.
The file examples.loose_agnostic.GAMS.farmer_example.bash has
three commands that mimic the commands for AMPL. The GAMS bash script
is not part of the automated tests because I don’t want to deal with
the license.
A somewhat strange example is in the file
examples.sizes.mps_demo.bash has two commands. The second
illustrates how to instruct MPI-SPPY to read mps/json file pairs
for each scenario from a directory. The first command illustrates how
to use MPI-SPPY to write them in the first place (but if
MPI-SPPY can get your scenarios, there is probably no reason to
write them and then read them again!). This functionality is intended
to be used by users of other AMLs or other scenario-based stochastic
programming applications.
Either .lp or .mps files can be used for the scenario models. The
code that creates a Pyomo model from a model file is in
mpisppy.problem_io.mps_reader.py.
JSON file format
The directory named in the --mps-files-directory needs to have
two files for each scenario: a model file (.mps or .lp) and a json
file. An optional third file, {scenario}_rho.csv, supplies per-nonant rho
values (see Per-nonant rho file (optional) below). The json
file need to have certain literal strings as well as scenario-specific
data. In this specification, scenario specific data is named with underscores.
Note that the total number of tree nodes is given as an integer, but the file
only contains the data for nodes for the single scenario.
{
"scenarioData": {
"name": scenario_name,
"scenProb": scenario_probability,
},
"treeData": {
"globalNodeCount": number_of_nodes_in_entire_tree,
"nodes: {
"ROOT": {
"condProb": 1.0,
"nonAnts": [
"first_root_node_nonant_name",
"second_root_node_nonant_name",
#...
]
}
"ROOT_i": {
"condProb": conditional_probability_of_second_stage_node_i,
"nonAnts": [
first_nonant_name_at_node,
second_node_nonant_name_at_node,
#...
]
}
}
}
}
Two-stage JSON example
Two-stage problems are simple because there is only one node in the scenario tree and its name must be ROOT. Here is an example
{
"scenarioData": {
"name": "unknown",
"scenProb": 0.3333333333333333
},
"treeData": {
"globalNodeCount": 1,
"nodes": {
"ROOT": {
"serialNumber": 0,
"condProb": 1.0,
"nonAnts": [
"NumProducedFirstStage(1)",
"NumProducedFirstStage(2)",
"NumProducedFirstStage(3)",
# ...
"NumUnitsCutFirstStage(10_10)",
]
}
}
}
}
Naming Conventions
Scenario names should end in a serial number. Zero-based numbering is best, but one-based is supported.
The root node of the scenario tree must be named ROOT.
Other nodes must begin with the name of the parent node and end with an underscore followed by a zero-based serial number for the node at its stage.
The names of the nonanticaptive variables at the node are given in the nonAnts list and the names must match the variable (column) names in the model file (
.mpsor.lp).
Per-nonant rho file (optional)
You can optionally supply a {scenario}_rho.csv file for each scenario in
the --mps-files-directory. When present, mps_module uses it to set
per-nonant rho values for PH; when absent, rho falls back to --default-rho.
The file has a header line and one row per nonanticipative variable:
varname,rho
NumProducedFirstStage(1),1.0
NumProducedFirstStage(2),1.0
# ...
The varname column uses the same variable names as the nonAnts list in
the json file (a fullname header is also accepted). A rho file should cover
every nonant; pass --default-rho as a backstop for any nonant that is not
listed.
Consistency is the writer’s responsibility. PH requires the same rho for a given nonant at a tree node across every scenario that passes through that node. mpi-sppy applies these rhos per scenario and does not check cross-scenario consistency, so an inconsistent set of rho files silently yields an ill-defined run.
Tight integration
From the end-user’s perspective
When mpi-sppy is used for a model developed in an AML for which support
has been added, the end-user runs the mpisppy.agnostic.agnostic_cylinders.py
program which serves as a driver that takes command line arguments and
launches the requested cylinders. The file
mpisppy.agnostic.go.bash provides examples of a few command lines.
From the modeler’s perspective
Assuming support has been added for the desired AML, the modeler supplies two files:
a model file with the model written in the guest AML (AMPL example:
mpisppy.agnostic.examples.farmer.mod)a thin model wrapper for the model file written in Python (AMPL example:
mpisppy.agnostic.examples.farmer_ampl_model.py). This thin python wrapper is model specific.
There can be a little confusion if there are error messages because both files are sometimes refered to as the model file.
Most modelers will probably want to import the deterministic guest model into their python wrapper for the model and the scenario_creator function in the wrapper modifies the stochastic paramaters to have values that depend on the scenario name argument to the scenario_creator function.
(An exception is when the guest is in Pyomo, then the wrapper file might as well contain the model specification as well so there typically is only one file. However, there is not particularly good reason to use the agnostic machinery for a Pyomo model.)
From the developers perspective
If support has not yet been added for an AML, it is almost easier to
add support than to write a guest interface for a particular model. To
add support for a language, you need to write a general guest
interface in Python for it (see, e.g., ampl_guest.py or
pyomo_guest.py) and you need to add/edit a few lines in
mpisppy.agnostic.agnostic_cylinders.py to allow end-users to
access it.
Special Note for developers
The general-purpose guest interfaces might not be the fastest possible
for many guest languages because they don’t use indexes from the
original model when updating the objective function. If this is an issue,
you might want to write a problem-specific module to replace the guest
interface and the model wrapper with a single module. For an example, see
examples.farmer.agnostic.farmer_xxxx_agnostic, where xxxx is replaced,
e.g., by ampl.
Architecture
The following picture presents the architecture of the files.
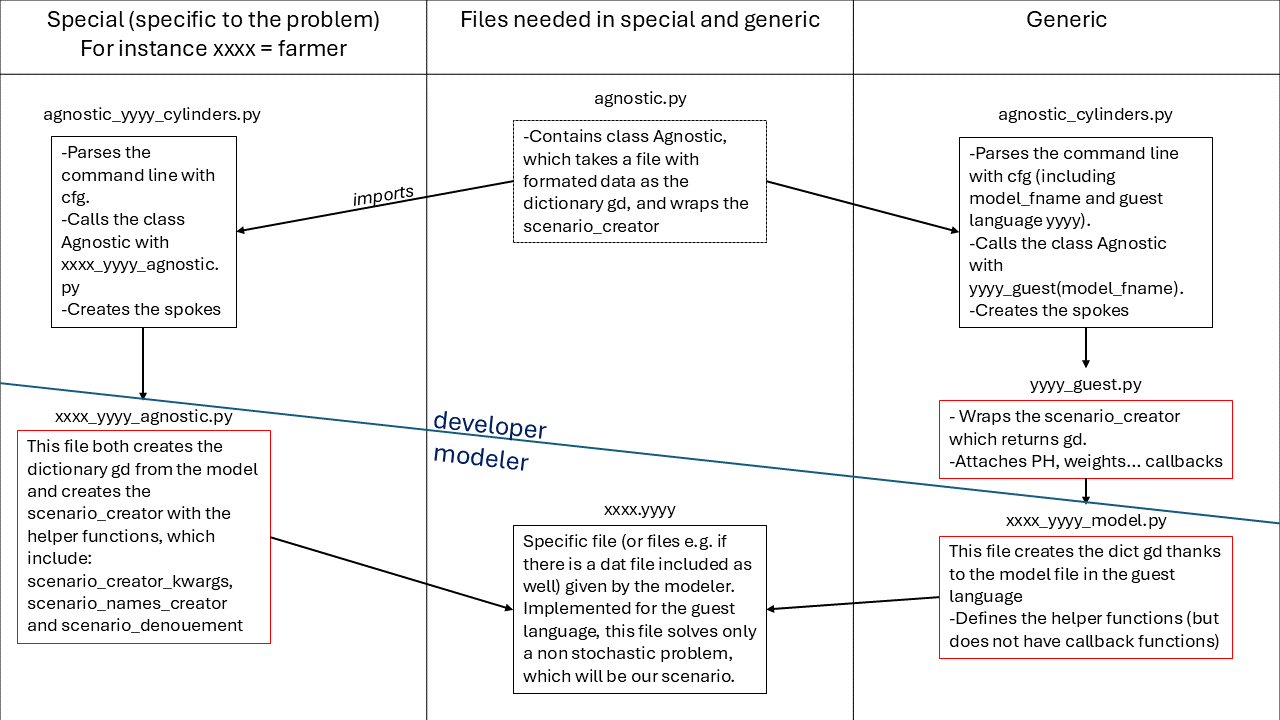
We note “xxxx” the specific problem, for instance farmer. We note “yyyy” the guest language, for instance “ampl”.
Two methods are presented. Either a method specific to the problem, or a generic method.
Regardless of the method, the file agnostic.py and xxxx.yyyy need to be used.
agnostic.py is already implemented and must not be modified as all the files presented above the line “developer”.
xxxx.yyyy is the model in the guest language and must be given by the modeler such as all the files under the line “modeler”.
The files agnostic_yyyy_cylinders.py and agnostic_cylinders.py are equivalent.
The file xxxx_yyyy_agnostic.py for the specific case is split into yyyy_guest.py and xxxx_yyyy_model.py for the generic case.
It is worth noting that the scenario creator is defined in 3 files.
It is first defined in the file specific to the problem and the guest language xxxx_yyyy_model.py. At this point it may not return a scenario.
It is then wrapped in a file only specific to the language yyyy_guest.py. At chich point it returns the dictionary gd which indludes the scenario.
Finally the tree structure is attached in agnostic.py.
Bundles
The use of scenario bundles can dramatically improve the performance
of scenario decomposition algorithms such as PH and APH. Although mpi-sppy
has facitilites for forming bundles, the mpi-sppy
agnostic package assumes that bundles will be completely handled
by the guest. Bundles will be returned by the scenario creator function
as if they are a scenario. Although it seems sort of like a trick, it is
really the way bundles are intended to operate so we sometimes refer to
true bundles, which are used in non-agnostic way as briefly
described in section Proper Bundles.
Overview of Recommended Bundle Practices
Modify the scenario creator function so that if the scenario name starts with the string “scen” it returns a single scenario, but if the name starts with “bundle” it returns the full extensive formulation for a group of scenarios (i.e. a bundle). We typically number scenarios and the scenario or bundle number is at the end of the first positional argument for the scenario creator function (i.e. at the end of the scenario name).
If the name starts with bundle, the scenario creator function can call itself with the proper list of scenario names to get the scenarios to form the EF that will be returned. We recommend names for bundles such as “bundle_xxx_yyy” where xxx and yyy give the first and last scenario number in the bundle. You could also pass in a dictionary that maps bundle numbers to lists of scenario numbers as a keyword argument to the scenario_creator function and then append the bundle number to “bundle” and pass it as the positional scenario name argument to the scenario creator function.
Some notes
The helper function called
scenario_names_creatorneeds to be co-opted to instead create bundle names and the code in the scenario_creator function then needs to create its own scenario names for bundles. At the time of this writing this results in a major hack being needed in order to get bundle information to the names creator in the Pyomo example described below. You need to supply a function calledbundle_hackin your python model file that does whatever needs to be done to alert the names creator that there bundles. The function takes the config object as an argument. Seempisppy.agnostic.farmer4agnostic.pyThere is a heavy bias toward uniform probabilities in the examples and in the mpi-sppy utilities. Scenario probabilities are attached to the scenario as
_mpisppy_probabilityso if your probabilities are not uniform, you will need to calculate them for each bundle (your EF maker code can do that for you). Note that even if probabilities are uniform for the scenarios, they won’t be uniform for the bundles unless you require that the bundle size divides the number of scenarios.There is a similar bias toward two stage problems, which is extreme for the agnostic package. If you have a multi-stage problem, you can make things a lot easier for yourself if you require that the bundles contain all scenarios emanating from each second stage node (e.g., on bundle per some integer number of second stage nodes). This is what is done in (non-agnostic) Proper Bundles. The result of this is that your multi-stage problem will look like a two-stage problem to mpi-sppy.
Example
The example mpisppy.agnostic.farmer4agnostic.py contains example code.
Note
In order to get information from the command line about bundles into the
scenario_names_creator the bundle_hack function is called
called by the cylinders driver program very early. For this example,
function sets global variables called bunsize and numbuns.
The script mpisppy.agnostic.examples.go.bash runs the example (and maybe some
other examples).
Notes about Gurobipy
The current implementation of gurobipy assumes that nonants that are in the objective function appear direclty there (not via some other variable constrained in some way to represent them).